
Hello! You're looking at my portfolio, I will upload my reflections about the lectures and workshops every week after my classes. Please feel free to view everything.
About my regular using website
I often use the web version of the Xiaohongshu (https://www.xiaohongshu.com/explore).
It is a website like an online society, for users to share whatever they are interested in and also free to look through others’ sharing notes.
I prefer this website because I like the concise page design. The page can show more user notes on one page, and the interface is easier to use than the mobile application version. It's similar to the mobile version of Xiaohongshu, but it only has the note recommendation and retrieval functions, without the e-commerce service in the app. This makes the web version a neater and clearer way to browse.
On top of that, one of the mobile games I play has a lot of players who share game tips on Xiaohongshu, mostly in video format. I can use my laptop to watch the videos on the web page while I'm playing the game on my mobile phone (in case I don't have an iPad and other mobile phones).
I think the web page should be optimised for 'My Account' section. I can't see my note history during using the website, which makes it tricky to find a note I've already seen but not tagged (liked or collected into my private album). Also, when posting content on the web version of Xiaohongshu, I have to go to the dedicated creation service platform, which I think could be done on the original page when posting simple graphic notes.
About my study on website languages
Before I got into digital practices, I'd never come across web languages or anything to do with websites. HTML and CSS were completely new to me, but they weren't at all difficult to understand. When I turned on developer tools in class to look at web pages that I thought were pretty simple, I have to say that HTML and CSS are far more complex than I thought.
I used to find it tricky to change colours in CSS and partition in HTML when I was working on my own website design. But now I've got to grips with it. I've learned a lot from the links listed in the course assignment.
Feedback
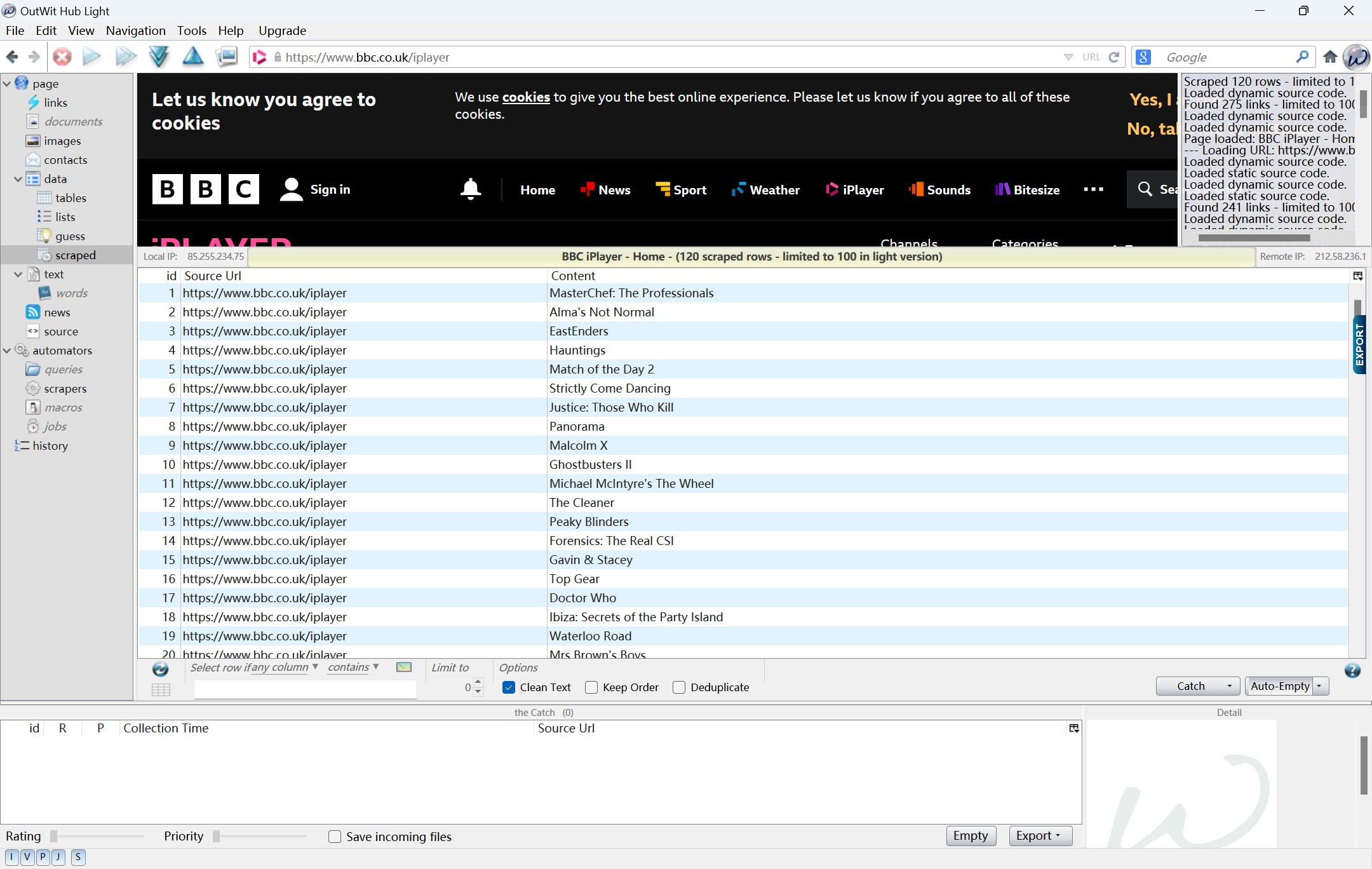
In the Week 3 workshop, I learned how to use different web scraping tools to collect data from web pages. These tools include Outwit, Webscraper.io, and Python etc. I have tried out various tools and I think they are surely great alternative to manual statistics.
I had some thoughts about selecting and identifying data after week 3 workshop. I think scraping tools make our works easier, but the ability to spot valuable data is still crucial . With the help of efficient and convenient tools, it is even more important for us that we should understand what kind of data is worth collecting and analyzing.
Same as the web language learned in week 2, I had some difficulty learning how to scarpe a website. The first and biggest challenge I faced was to get familiar with the various web scraping tools. As a beginner, I could barely keep up with the class despite the detailed tutorials for learning the various tools. After the class, I went over the procedures of these software on the workshop handbook again.
Feedback on workshop questions
During the week4 workshop, we joined discussions in groups and shared our ideas on the padlet group link. (https://universityofleeds.padlet.org/hsteel11/comm5780m-week-4-workshop-1-group-3-ul6ruj844iijnwfq).
Our group chose scenario 2 (university-led data collection) and we decided to use the StREAM@leeds to collect the study and using data in campus (e.g. average engagement, library visits).
The workshop question just fixed to what I considered after the week3 workshop: we should collect an exact type of data and try to find the values that effect them. By thinking about how data is collected, where it is collected, and ethical considerations of data, I have come to realise that collecting data is not as simple as one might think. In order to efficiently cope with huge data, we have to choose online resources and modern tools. After deciding on the data we want to collect, we need to carefully check the issues of user privacy. We also discussed the variables that would affect this data, including factors such as gender, nationality, time period, etc. I think we need to further think about how the selection of these factors would be significant to our research in class, as well as building our data set.
Related to the reading What Get Counted Counts…
I believe that I need to pay particular attention to the following points in my future data collection. Firstly, it is important to avoid simple binary categorization of data, such as ‘male/female’ or ‘black/white’, as these categorizations may not be able to contain a diverse group of people. Customization options can be provided to make the data a more realistic reflection of different identities and experiences. Data collection should also take into account multicultural contexts. We should try to use collecting methods that are adapted to different cultures, genders and backgrounds in order to gain more comprehensive insights in our research. Secondly, data involving personal privacy should be collected with the permission of the person being collected. Especially when it comes to gender, ethnicity and minority identities, ensuring the anonymity of data and informed consent for collection is important.
The things surprised/challenged me……
As we have already finished the week5 workshop today, I would like to talk about the data visualization we have done during the class time. It was quite surprising when the tutor showed us some examples of data visualization. The works were succinct but full of details. Or I should say I found that these works are focusing on how to accurately show the key data to the audiences. It inspired me that data visualization is not just a pattern of showing our skills on designing, but also an art to vividly display numbers and arouse resonation.
Collecting data, on the other hand, was more challenging than I expected. In class, even though we selected the data we wished to collect after discussion, we encountered many difficulties in practice. As stated in the reflection for week4, if we wished to use the data we had collected for the following analysis, I think we struggled to collect a large amount of valid data entirely on our own. In fact, in week5's workshop, we did eventually give up using the data we collected ourselves because of the small amount of data we collected and the inaccuracy of the data sources.
What I learned from the workshop questions……
When talking about considering the audiences for our data visualization, I think it has given me a deeper understanding of the purpose and intent of data visualization. Factors such as the audience's receptivity and what we expect them to achieve should be important considerations in the process of data visualization. When we thought about ‘what changes and actions do we want our audience to take after seeing our visualizations’, one of our answers was that we want them to push themselves to improve their individual data (because it's a record of their learning behaviors). It was at this point that I realized, after shifting the roles from audience to collectors, they tend to think in terms of being more idealistic and might stand at a position of upper class.
How do data visualizations help us understand and communicate data?
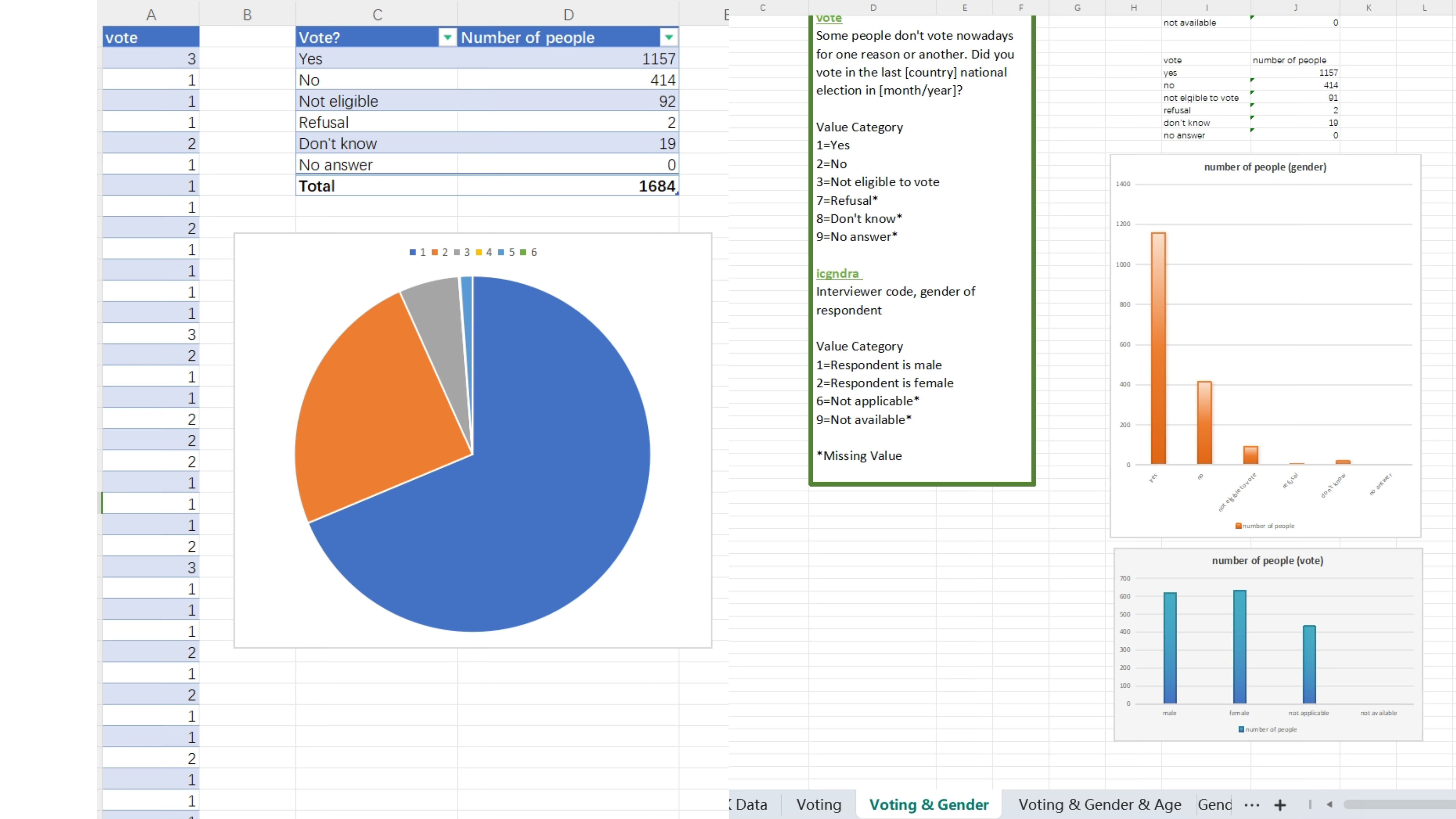
Visualizing data allows us to find the data we want more quickly and clearly when we are faced with huge amounts of data (for example on workshop we chose the data set about voting. The types of voters and the types of votes they cast were about 5 types. At this point it would have been almost impossible if we had tried to go to manual searching or counting data manually).
What are the challenges of data visualizations?
1. Screening and organizing the raw data (invalid data, no one chooses certain options, data size is too large)
2. How to choose the right type of visualization (existing visualization tools are very diverse, for example, in excel we should judge when to use what kind of charts)
3. How to balance aesthetics and data presentation (the design should not be too fancy and ignore the data visualization itself is used to present data)
This is our padlet link for group discussion (also some screenshots on it):
(https://universityofleeds.padlet.org/hsteel11/comm5780m-week-7-workshop-1-10-00-12-00-3roq5zqt47h1epv8).
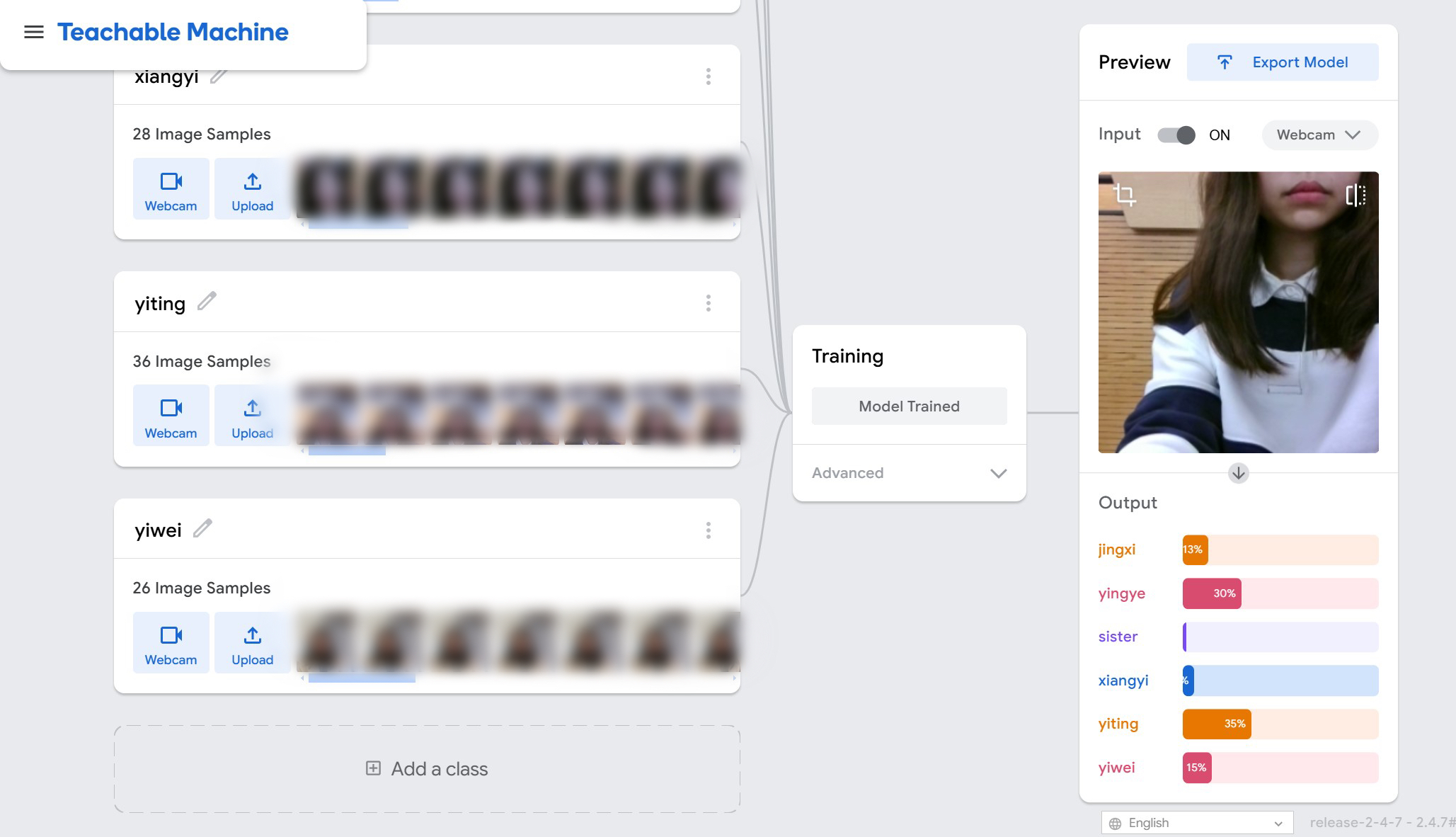
What I learned from training my own model……
The first thing that strikes me about training models is the power of technology. Instead of relying on simple human power, we can now train models to accomplish the tasks we wish to. And I also appreciated the complexity of the modeling algorithms behind it. Although the model simplifies the user's operations, it represents a large and intelligent algorithm for running the data. At the same time, while performing the task of tricking the model so that it can't accurately recognize faces, I felt that even if the model is so advanced, it still needs manual method as an aid. In today's video review process, the review department should use this model to identify offending content through large-scale initial screening, and then conduct manual secondary review to improve the accuracy of the review.
Related to the reading……
Through reading, I learned about the historical background that lies behind today's facial recognition technology. This literature gives some inspiration on how to deal with the potential bias and discrimination in facial recognition technology.
First of all, the author points out the racial and gender bias behind facial recognition technology. The ‘objectivity’ of the technology tends to mask the underlying social bias, which slowly becomes embedded in social development and even becomes a normalized cultural common sense in our society. I believe that while using these advanced technologies, we should discover and reflect on the historical roots of colonization behind them, so as to avoid unconsciously perpetuating the colonial power structure.
Secondly, I believe that facial recognition technologies should be developed in such a way that they can serve multiple social needs and groups, and help empower marginalized groups rather than further exacerbate the plight and discrimination they face. Ethical considerations should not be limited to the realization of ‘fair’ algorithms, but should also include critical thinking about the nature and uses of technology.
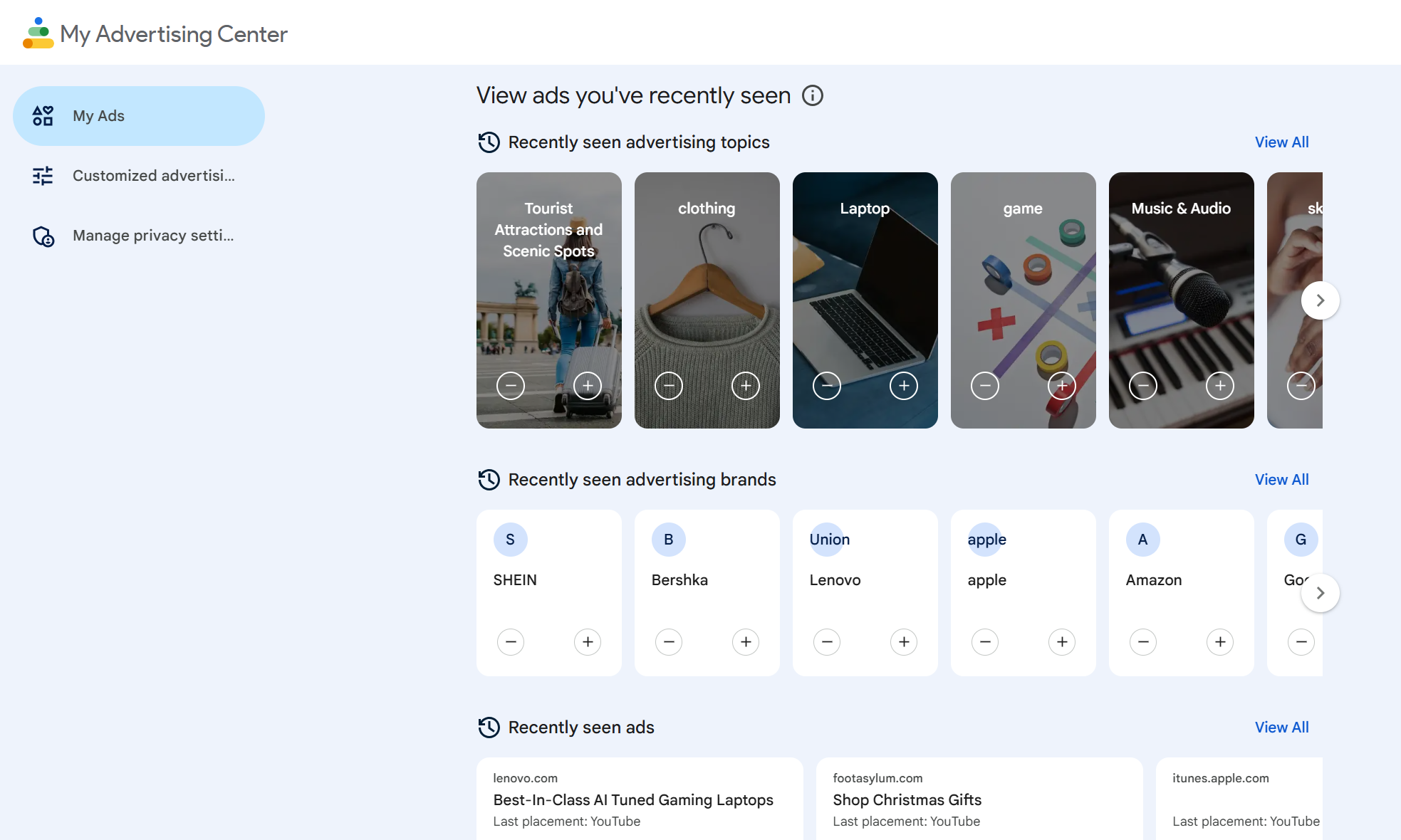
What I learned from exploring my data……
The first thing that struck me in exploring data about me was the fact that we are unconsciously having all sorts of data collected by social media. In some words, though we are often asked if we accept cookies from a website, or regulations on the use of a software, most of the time we don't have a clear idea of what kind of data we are being collected on. For example, on workshop I chose to see what type of data Instagram collected on me. After I clicked on ‘Your activity’ I saw more types of data than I thought. Whose posts I liked and commented on, what changes I made to my account settings and at what time, what adverts I interacted with ...... Social media records my every move on the web and after analysing and learning from my data, it shapes into something that is more in line with my usage habits and personal preferences.
In class we were asked to think about ‘whether the data collected by social media can be an introduction to us in real life’. For example, Google Chrome is constantly collecting our browsing traces, and based on these records, it makes inferences about our preferences and eventually pushes adverts to us in similar areas. (Our group found that as university students, we were often pushed information about student housing rentals. I presume this is because our records of visits to university websites and location information are analysed) Some software also tags users based on these adverts. I think this is just a generalised label based on my web browsing behaviour, but it doesn't represent a ‘whole’ me.
From catagorising my friends……
When categorising posts posted by my friends, I don't think I could define most of them as a particular type. They often contain more complex information, which makes me spend more time thinking and making choices when manually determining which type a post belongs to. In relation to myself, I'm even more convinced that the existing social platform labels don't fully, or accurately, represent myself. However, I don't think that machine recognition is pointless. First of all, it can improve our efficiency (manual method is very slow), and also can avoid subjectivity to a certain extent (sometimes we will subjectively ignore certain aspects in self-definition, or intentionally show the part we want to show to the public). But at the same time it occurs to me that the rules determined by the machine are code made by humans, so do absolutely objective rules really exist?
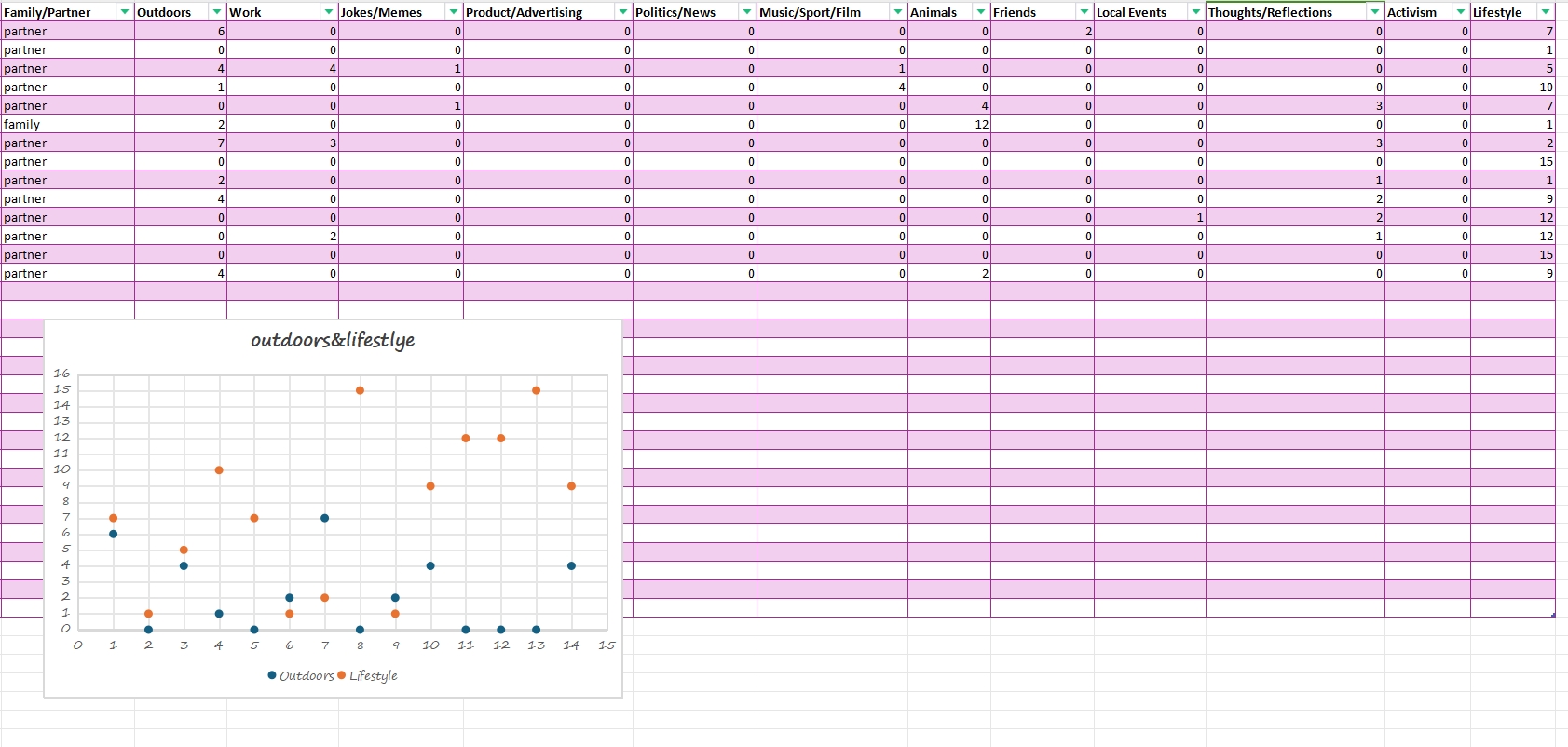
The changes I would make to Sumpter's method……
I think firstly the method or the types of categories could be redefined. Doing so would make the types more detailed and would also allow the categorization working on more complex judgment situations, such as the situation that different types of photos under the same tweet. Secondly, I think we can take into account the differences in posting times for different users. For example, some tweets are spaced far apart in time, so we need to take into account the fact that instead of simply selecting only the 15 most recent tweets, we can qualify the time period when recording tweets.
How else might you investigate your friend's online identities?
In addition to categorizing the published tweets, we can also capture the information in their profile that they show to the public. For example, taking Weibo as an example, we can see that the profile also shows the user's gender, age, profile, icon and so on. At the same time, we can also see the user's participation in topics. I think all this information can be helpful to analyze the user's online personal perception.
What I learned from exploring a digital community……
Through exploring a digital community, I think it is a very suitable place to study audience ecology. Digital community can transcend the limitations of time and space, not only can we reach users from different regions and cultures in our research, but also we can do real-time observation of the dynamics of the online community. However, I think it is also necessary to consider ethics and privacy when making these observations. If we want to use the content of a digital community as part of our research data, we need to carefully determine what content can be used in our research, and we also need to obtain informed consent from the users.